A while back, I started blogging about /dev/kcore and had gotten up to the task_struct structure, promising to continue talking about it. Well, it's been a while since, but I have not forgotten. This will take more than one post to finish it up, however. Today we will start with a brief introduction. Later posts will continue our exploration concluding with some small real demonstrations.
task_struct
So what is the task_struct structure? It's a structure that contains information about what a process is doing. It allows the kernel to keep track of processes that are running, the states they are in as well as other information needed by that process during execution.
States of the process are also defined in include/linux/sched.h and let the kernel know if the process is running (TASK_RUNNING), interruptible (TASK_INTERRUPTIBLE), uninterruptible (TASK_UNINTERRUPTIBLE), stopped (TASK_STOPPED), being traced by a debugger (TASK_TRACED), or exiting (EXIT_ZOMBIE, EXIT_DEAD).
The task_struct structure also contains identifying information such as the process PID, thread group leader ID. There are also pointers to the parent process' task_struct structure and real_parent task_struct structure for debugging purposes.
Also contained in the task_struct structure is information about other relationships the current process has such as children or siblings.
The executable name excluding the path is also stored in task_struct as well as current directory information and file descriptors.
The signal_struct structure contains information regarding signals for this process as well as tty associated with it.
Also contained in the task_struct is the mm_struct which contains pointers to vm_area_structs which are areas of virtual memory. We will discuss mm_struct and vm_area_struct next time.
References:
Bovet, D., M. Cesati (2000). Understanding the linux kernel. Cambridge: O'Reilly Media.
Rusling, D. Virtual Memory, The Linux Tutorial http://www.linux-tutorial.info/modules.php?name=MContent&pageid=322
Sunday, December 20, 2009
Audience Participation Time
While catching up on some reading over at Harlan's blog I started thinking about all of the programming I've done in the past year or so. I really appreciate all of the hard work that goes into developing programs like RegRipper and countless others. It's cool when people are able to share tools they have developed to solve problems they have encountered in the field. It's also cool when people who are in the field are able to solve the problems themselves. I have been thinking about whether or not someone who is working in the field of digital forensics really needs to know a programming language or not. My thoughts are yes (which is influenced by what I see around me and may be biased, considering that I do a lot of programming), but I can see how some people may think differently. The reason why I bring this up is because this question has been in the back of my mind since my last discussion with someone from my alma mater, John Jay College.
John Jay's MS in Forensic Computing has been established since 2004 and it has been evolving ever since its conception. The courses of the program have roughly contained a lot of hands on labs as well as theory (algorithms, cryptography, network protocols etc) and programming (various scripting, C Linux OS) in addition to Criminal Justice courses on laws regarding digital evidence. The question has come up several times as to whether or not the theoretical and programming courses are needed in the background of someone who wants to be a forensic examiner.
When I was in attendance there, the general feeling from *some* (not all) of my colleagues was that they didn't need to learn programming and theory in order to work as a forensic examiner. They said they only needed to learn how to use tool XXX or YYY and get a certification in A, B, and/or C they would be set... Perhaps they were right in some way, as they went on to find jobs where that was enough for them. The debate continues about the direction of the program and whether or not theory and programming are needed and whether or not some kind of certification should be obtained instead.
Having been out in the "real world" for a little while, I see a lot of people who do not need any programming knowledge whatsoever to fulfill their jobs. There are plenty of tools that they are more than proficient in using and I'm not knocking their skills, because they are really quite knowledgeable at what they do. However, there are many times that tool XXX or tool YYY doesn't do whatever it should normally, or it cannot fulfill the job the way the client would like. Having a little programming knowledge helps out immensely in these cases. In addition to the EnScripts I have written at work, I have written a lot of Perl scripts, *nix scripts, Visual Basic programs, SQL queries etc. to get the job done. I have also taken someone else's code in language X, Y or Z and tweaked it to run the way I needed it to for a particular job. Now I concede that it's not every day that I need to write these customizations, but it happens enough that I'm glad I can do it.
I often hear from colleagues at work or elsewhere that they wish they knew how to program in X or Y so they could write their own tools to do something. I have suggested books or websites from which they could glean this wanted knowledge. This often comes with some "stern" advice that they must also practice programming if they want it to stick. Some have taken my advice, some probably just don't have the time for it...
So after much rambling on the subject, what do you think? How often do you wish/are you glad that you knew how to program? How often would it have helped you/does it help you on your job as a forensic examiner/incident responder?
Don't be afraid to comment. I only moderate to keep down on the spam (which I seem to get a lot of for some reason).
John Jay's MS in Forensic Computing has been established since 2004 and it has been evolving ever since its conception. The courses of the program have roughly contained a lot of hands on labs as well as theory (algorithms, cryptography, network protocols etc) and programming (various scripting, C Linux OS) in addition to Criminal Justice courses on laws regarding digital evidence. The question has come up several times as to whether or not the theoretical and programming courses are needed in the background of someone who wants to be a forensic examiner.
When I was in attendance there, the general feeling from *some* (not all) of my colleagues was that they didn't need to learn programming and theory in order to work as a forensic examiner. They said they only needed to learn how to use tool XXX or YYY and get a certification in A, B, and/or C they would be set... Perhaps they were right in some way, as they went on to find jobs where that was enough for them. The debate continues about the direction of the program and whether or not theory and programming are needed and whether or not some kind of certification should be obtained instead.
Having been out in the "real world" for a little while, I see a lot of people who do not need any programming knowledge whatsoever to fulfill their jobs. There are plenty of tools that they are more than proficient in using and I'm not knocking their skills, because they are really quite knowledgeable at what they do. However, there are many times that tool XXX or tool YYY doesn't do whatever it should normally, or it cannot fulfill the job the way the client would like. Having a little programming knowledge helps out immensely in these cases. In addition to the EnScripts I have written at work, I have written a lot of Perl scripts, *nix scripts, Visual Basic programs, SQL queries etc. to get the job done. I have also taken someone else's code in language X, Y or Z and tweaked it to run the way I needed it to for a particular job. Now I concede that it's not every day that I need to write these customizations, but it happens enough that I'm glad I can do it.
I often hear from colleagues at work or elsewhere that they wish they knew how to program in X or Y so they could write their own tools to do something. I have suggested books or websites from which they could glean this wanted knowledge. This often comes with some "stern" advice that they must also practice programming if they want it to stick. Some have taken my advice, some probably just don't have the time for it...
So after much rambling on the subject, what do you think? How often do you wish/are you glad that you knew how to program? How often would it have helped you/does it help you on your job as a forensic examiner/incident responder?
Don't be afraid to comment. I only moderate to keep down on the spam (which I seem to get a lot of for some reason).
Saturday, December 19, 2009
More Misc Stuff
I recently came across a couple of tools that may be helpful to someone and I have created a repository for some of my stuff:
Maatkit
Maatkit has a lot of cool utilities that allow you greater control of MySQL. I recently found it very useful for restoring an extremely large MySQL dump by using the mk-parallel-restore. For information about its feature, either visit the website or you can check out this Linux Magazine article.
HTMLDOC
HTMLDOC allows you create PDF documents of html pages. You can convert pages one page at a time, or as a book. So you could use wget to download the pages of a website recursively, including the graphics and then pdf'ify it into one book with references... pretty useful.
Some of my stuff
Since I'm not sure how much longer I will have my academic website, I am starting to move some of the code that's been hosted there to another location. I have also added a few things that are not listed on the old code page or elsewhere on my academic site, such as a DC3 Image Assember script that worked with the last DC3 challenge (haven't looked at the current one) and a Virus Total hash checker that takes a list of hashes and posts them to Virus Total to build an html report. This last one needs some modification however, since if one is checking lots of files Virus Total starts to report errors... Hopefully I'll have some time to create a new version in the future...
Maatkit
Maatkit has a lot of cool utilities that allow you greater control of MySQL. I recently found it very useful for restoring an extremely large MySQL dump by using the mk-parallel-restore. For information about its feature, either visit the website or you can check out this Linux Magazine article.
HTMLDOC
HTMLDOC allows you create PDF documents of html pages. You can convert pages one page at a time, or as a book. So you could use wget to download the pages of a website recursively, including the graphics and then pdf'ify it into one book with references... pretty useful.
Some of my stuff
Since I'm not sure how much longer I will have my academic website, I am starting to move some of the code that's been hosted there to another location. I have also added a few things that are not listed on the old code page or elsewhere on my academic site, such as a DC3 Image Assember script that worked with the last DC3 challenge (haven't looked at the current one) and a Virus Total hash checker that takes a list of hashes and posts them to Virus Total to build an html report. This last one needs some modification however, since if one is checking lots of files Virus Total starts to report errors... Hopefully I'll have some time to create a new version in the future...
Sunday, December 13, 2009
Misc Stuff
Droid Forensics
For those of you interested in Droid forensics, check out the viaForensics website. There you can find a presentation on Droid forensics (pdf) as well as a regularly updated blog.
New Volatility Plugins
MHL has been busy creating new Volatility plugins. He's modified the malfind plugin to use YARA which allows one to search the process memory for defined patterns (rules). He also has created a new plugin called ldr_modules.py that can detect unlinked LDR_MODULE entries. I suggest reading his blogpost in order to take it all in. You can get the updated plugins here (zip).
Also from his blogpost you'll see that AAron and Moyix rocked the Incident Detection Summit.
MDD will cease to exist
It seems that development and maintenance of the MDD tool will cease. For those of you who are dependent on that tool, windd is a great free alternative.
Into the Boxes
For those of you who might not be aware, there is a new quarterly digital forensic and incident response ezine that is about to come out next month called Into the Boxes. For more updates, check out their twitter feed. If you are interested in contributing to future publications, you can find the guidelines here.
For those of you interested in Droid forensics, check out the viaForensics website. There you can find a presentation on Droid forensics (pdf) as well as a regularly updated blog.
New Volatility Plugins
MHL has been busy creating new Volatility plugins. He's modified the malfind plugin to use YARA which allows one to search the process memory for defined patterns (rules). He also has created a new plugin called ldr_modules.py that can detect unlinked LDR_MODULE entries. I suggest reading his blogpost in order to take it all in. You can get the updated plugins here (zip).
Also from his blogpost you'll see that AAron and Moyix rocked the Incident Detection Summit.
MDD will cease to exist
It seems that development and maintenance of the MDD tool will cease. For those of you who are dependent on that tool, windd is a great free alternative.
Into the Boxes
For those of you who might not be aware, there is a new quarterly digital forensic and incident response ezine that is about to come out next month called Into the Boxes. For more updates, check out their twitter feed. If you are interested in contributing to future publications, you can find the guidelines here.
Sunday, November 08, 2009
Briefly: New VDP Mac OSX Document
We have received a new submission to the VDP. Keep them coming :-)
Dougee has submitted an install manual for Snow Leopard. It covers installation from the official tar ball release as well as from the SVN repository. It also covers installing some of the plugin dependencies. Shouts to Dougee!
Dougee has submitted an install manual for Snow Leopard. It covers installation from the official tar ball release as well as from the SVN repository. It also covers installing some of the plugin dependencies. Shouts to Dougee!
Friday, November 06, 2009
OT: RSS Feeds and things
This is not going to be my usual banter, just something I came across (yeah, I know, I'm late) and thought was cool. So it's no big secret that I use Google's Reader to keep up with all of my RSS feeds. I had noticed that we are now able to search for shared items and hadn't really given it much thought. I had even shared a couple of articles earlier in the year, but didn't really know what happened to them, or forgot that I had done so...
Anyway, the other day people on twitter were talking about Google Dashboard and I decided to check it out. There really wasn't that much surprising until I looked under the "Reader" section and saw I had followers. Followers? For my Google reader? I wanted to know what they were following. So after some investigation I find my shared items feed with the two things I had shared previously. I've since decided to add things to the feeder, sometimes even with notes :-)
I know... Google's got the goods on me and I'm feeding the monster, black helicopters etc etc etc... but it's still a cool way to share things you read. I've since subscribed to a few feeds myself :-)
Anyway, the other day people on twitter were talking about Google Dashboard and I decided to check it out. There really wasn't that much surprising until I looked under the "Reader" section and saw I had followers. Followers? For my Google reader? I wanted to know what they were following. So after some investigation I find my shared items feed with the two things I had shared previously. I've since decided to add things to the feeder, sometimes even with notes :-)
I know... Google's got the goods on me and I'm feeding the monster, black helicopters etc etc etc... but it's still a cool way to share things you read. I've since subscribed to a few feeds myself :-)
Sunday, October 25, 2009
Briefly: New Volatility Release
(via Echo6)
There is a new stable release of Volatility v 1.3.2 available for download.
Also Michael Cohen (scudette) and Mike Auty have been extremely busy developing. Their fearless efforts could use some eyes to track down and report bugs, however. If you feel like helping out, download the 1.3.2 version, test it out and report any bugs you may find.
You may report bugs using the Issues feature on the Google Code site. You may also reach Mike Auty at:
mike {dot} auty {at} gmail {dot} com
And of course you can always reach the Volatility team on IRC on the #volatility channel at irc.freenode.net
Mike Auty (ikelos) and Michael Cohen (scudette) are often online so you can talk to them about any bugs you encounter directly.
There is a new stable release of Volatility v 1.3.2 available for download.
Also Michael Cohen (scudette) and Mike Auty have been extremely busy developing. Their fearless efforts could use some eyes to track down and report bugs, however. If you feel like helping out, download the 1.3.2 version, test it out and report any bugs you may find.
You may report bugs using the Issues feature on the Google Code site. You may also reach Mike Auty at:
mike {dot} auty {at} gmail {dot} com
And of course you can always reach the Volatility team on IRC on the #volatility channel at irc.freenode.net
Mike Auty (ikelos) and Michael Cohen (scudette) are often online so you can talk to them about any bugs you encounter directly.
Wednesday, October 21, 2009
Volatility Get Plugins Bash Script
Earlier I had written about all of the known Volatility plugins and how to go about installing them. Now I've decided to make things even easier for some, by including a bash script that will download and install all of these plugins. It will also install pefile, pycrypto and pydasm. I have tested it on a linux box as well as a cygwin installation.
Make sure you are running this as root (or with sudo) if you are doing this under Linux. Also make sure you have subversion installed.
Prereqs for Cygwin:
Obviously you must have Cygwin installed. In addition to what I have listed in a previous post, you will also need to install:
* wget
* unzip
* svn (subversion)
Hopefully I haven't forgotten anything... let me know if I have.
Simply unzip the bash script into the directory where you want Volatility installed. Then run the script:
This bash script removes one of the example files (memory_plugins/example3.py) since it has a conflicting _EPROCESS definition, so if you want that file - simply comment out that remove statement.
You will have to install Inline::Python yourself until I figure out a way to get it installed in a general fashion.
Let me know if you encounter errors.
Make sure you are running this as root (or with sudo) if you are doing this under Linux. Also make sure you have subversion installed.
Prereqs for Cygwin:
Obviously you must have Cygwin installed. In addition to what I have listed in a previous post, you will also need to install:
* wget
* unzip
* svn (subversion)
Hopefully I haven't forgotten anything... let me know if I have.
Simply unzip the bash script into the directory where you want Volatility installed. Then run the script:
$ ./get_plugins.bsh
This bash script removes one of the example files (memory_plugins/example3.py) since it has a conflicting _EPROCESS definition, so if you want that file - simply comment out that remove statement.
You will have to install Inline::Python yourself until I figure out a way to get it installed in a general fashion.
Let me know if you encounter errors.
Tuesday, October 20, 2009
Briefly: VDP Wiki
I have updated the VDP Wiki to include some blog posts out there about using or installing Volatility. There are also links to Richard McQuown's recent blogposts on his Volatility Batch File Maker and walk through. There are also links to other submitted articles on installation, usage and reporting.
I'll continue updating the Wiki as I find other articles to add to it. If anyone wants to add something new, let me know: jamie {dot} levy {at} gmail {dot} com
I'll continue updating the Wiki as I find other articles to add to it. If anyone wants to add something new, let me know: jamie {dot} levy {at} gmail {dot} com
Friday, October 09, 2009
Briefly: OMFW 2010
Open Memory Forensics Workshop (OMFW) 2010 is currently being planned. If you are interested in presenting or helping out, let them know!
Briefly: Malware Marketing talk at John Jay College
There's an upcoming talk at John Jay College next week that may interest some of you in the NYC area:
Understanding the Market for Malware and Cybercrime
Thursday, Oct. 15, 2009
3:15 pm, room 630T
Tom Holt, Assistant Professor
School of Criminal Justice
Michigan State University
Events will take place at
John Jay College of Criminal Justice
899 Tenth Avenue
(between 58th and 59th Streets.)
RSVP to Nicole Daniels (ndaniels@jjay.cuny.edu: 212.237.8920).
Understanding the Market for Malware and Cybercrime
Thursday, Oct. 15, 2009
3:15 pm, room 630T
Tom Holt, Assistant Professor
School of Criminal Justice
Michigan State University
Events will take place at
John Jay College of Criminal Justice
899 Tenth Avenue
(between 58th and 59th Streets.)
RSVP to Nicole Daniels (ndaniels@jjay.cuny.edu: 212.237.8920).
Monday, August 24, 2009
/dev/crash Driver
As you may or may not know, some distributions (RHEL, Fedora, Ubuntu) block some reads and writes to /dev/mem and have for a while. I first came across this when writing my thesis at John Jay College. Since I was trying to test the memory encryption library I had written and original tests comprised of scanning all of memory, the /dev/mem barrier was a bit cumbersome. I had gotten around it by using a Python script called Zeppoo-dump.py (project no longer maintained) to overwrite the offending instructions.
The following code only allows access within the first 256 pages of memory. (/usr/src/linux/drivers/char/mem.c):
and from (/usr/src/linux/arch/x86/mm/init_32.c):
You can find a nice writeup by Anthony Lineberry from BH Europe 2009.
So suppose you want to collect the memory image from /dev/mem? What will happen if you try to do so on a machine that has CONFIG_STRICT_DEVMEM enabled? If you try to collect memory using dd you will see the following:
You should also see the following in /var/log/messages though some values will obviously vary:
So there has be a way around this, right? Checking the Redhat Crash Utility listserv yielded some good advice. There are three courses of action proposed:
(1) Rebuild your kernel without the CONFIG_STRICT_DEVMEM restriction.
(2) Port the Fedora /dev/crash driver (./drivers/char/crash.c) to your kernel.
(3) Write a kretprobe module that tinkers with the return value of the
kernel's devmem_is_allowed() function such that it always returns 1.
I don't want to recompile the kernel since I'll loose whatever is currently in memory, so I'll focus on (2). Since I am currently using Ubuntu instead of Fedora, I knew I would have to port the code over. So I found a copy of crash.c and crash.h and set to work. You can find the ported crash driver here as well as a Makefile.
Now, I take NO responsibility for what may happen to your machine if something goes wrong during installation. This is for a 32bit system, and I have only tested this on Ubuntu Ibex kernel 2.6.27-14-generic. I still need to do some testing and will probably have more to say about that later... That being said, we'll continue.
Grab the tar file from above and extract:
Go inside the newly created folder and compile the kernel module:
At this point you should have the following files:
The file of interest is the crash.ko kernel module. We will load this into the kernel and check that it is installed correctly:
So now we have a new device we can use to access memory: /dev/crash
I'm not yet sure what the "Bad address" error means, but I suspect it is because dd tried to read beyond the 3.3 GB of memory that I have available.
You can remove the crash.ko module like so when you are finished:
Now let's test the newly obtained memory dump to see if it works. I'm going to use the RH Crash Utility with the volatile patch which you can find here:
So far so good :-)
In order to compile the kernel so that you can use the RedHat Crash Utility, you can follow the Ubuntu tutorial. After installing the appropriate packages you may have to run the following command:
You should end up with a linux-source*.tar.bz2 file under /usr/src . You should also have at least one folder with the kernel headers for your current kernel. You can extract the .tar.bz2 file as so:
Go into the resulting folder and set following flag in the Makefile:
Copy the .config file from your /usr/src/linux-headers-$(uname -r) folder into the /usr/src/linux-source-$(uname -r) folder.
Now type make. After the kernel is finished compiling, you should end up with a vmlinux file. This is the uncompressed kernel image with the debugging information that you need in order to run the RH crash utility.
For more information on the RH Crash Utility, check out:
Official RH Crash Utility Website
Linux Memory Forensics by A. Walters, M. Cohen and D. Collett.
slides from CEIC
The following code only allows access within the first 256 pages of memory. (/usr/src/linux/drivers/char/mem.c):
#ifdef CONFIG_STRICT_DEVMEM
static inline int range_is_allowed(unsigned long pfn, unsigned long size)
{
u64 from = ((u64)pfn) << PAGE_SHIFT;
u64 to = from + size;
u64 cursor = from;
while (cursor < to) {
if (!devmem_is_allowed(pfn)) {
printk(KERN_INFO
"Program %s tried to access /dev/mem between %Lx->%Lx.\n",
current->comm, from, to);
return 0;
}
cursor += PAGE_SIZE;
pfn++;
}
return 1;
}
#else
static inline int range_is_allowed(unsigned long pfn, unsigned long size)
{
return 1;
}
and from (/usr/src/linux/arch/x86/mm/init_32.c):
int devmem_is_allowed(unsigned long pagenr)
{
if (pagenr <= 256)
return 1;
if (!page_is_ram(pagenr))
return 1;
return 0;
}
You can find a nice writeup by Anthony Lineberry from BH Europe 2009.
So suppose you want to collect the memory image from /dev/mem? What will happen if you try to do so on a machine that has CONFIG_STRICT_DEVMEM enabled? If you try to collect memory using dd you will see the following:
# dd if=/dev/mem of=mem.dd
dd: reading `/dev/mem': Operation not permitted
2056+0 records in
2056+0 records out
1052672 bytes (1.1 MB) copied, 0.159965 s, 6.6 MB/s
You should also see the following in /var/log/messages though some values will obviously vary:
Aug 23 14:37:15 [comp name] kernel: [17415.953941] Program dd tried to access /dev/mem between 101000->101200.
So there has be a way around this, right? Checking the Redhat Crash Utility listserv yielded some good advice. There are three courses of action proposed:
(1) Rebuild your kernel without the CONFIG_STRICT_DEVMEM restriction.
(2) Port the Fedora /dev/crash driver (./drivers/char/crash.c) to your kernel.
(3) Write a kretprobe module that tinkers with the return value of the
kernel's devmem_is_allowed() function such that it always returns 1.
I don't want to recompile the kernel since I'll loose whatever is currently in memory, so I'll focus on (2). Since I am currently using Ubuntu instead of Fedora, I knew I would have to port the code over. So I found a copy of crash.c and crash.h and set to work. You can find the ported crash driver here as well as a Makefile.
Now, I take NO responsibility for what may happen to your machine if something goes wrong during installation. This is for a 32bit system, and I have only tested this on Ubuntu Ibex kernel 2.6.27-14-generic. I still need to do some testing and will probably have more to say about that later... That being said, we'll continue.
Grab the tar file from above and extract:
#tar -xvzf crash_driver_ubuntu.tgz
crash_driver/
crash_driver/crash.h
crash_driver/Makefile
crash_driver/crash.c
Go inside the newly created folder and compile the kernel module:
# cd crash_driver/
# ls
crash.c crash.h Makefile
# make
make -C /lib/modules/2.6.27-14-generic/build M=/home/levy/crash/crash_driver modules
make[1]: Entering directory `/usr/src/linux-headers-2.6.27-14-generic'
CC [M] /home/levy/crash/crash_driver/crash.o
Building modules, stage 2.
MODPOST 1 modules
CC /home/levy/crash/crash_driver/crash.mod.o
LD [M] /home/levy/crash/crash_driver/crash.ko
make[1]: Leaving directory `/usr/src/linux-headers-2.6.27-14-generic'
At this point you should have the following files:
# ls
crash.c crash.h crash.ko crash.mod.c crash.mod.o crash.o Makefile Module.markers modules.order Module.symvers
The file of interest is the crash.ko kernel module. We will load this into the kernel and check that it is installed correctly:
# insmod crash.ko
# lsmod |grep crash
crash 10368 0
# ls -l /dev/crash
crw-rw---- 1 root root 10, 59 2009-08-23 15:04 /dev/crash
# tail -n 1 /var/log/messages
Aug 23 15:04:10 [comp name] kernel: [19030.855920] crash memory driver: version 1.0
So now we have a new device we can use to access memory: /dev/crash
# dd if=/dev/crash of=crash.dd
dd: reading `/dev/crash': Bad address
6812680+0 records in
6812680+0 records out
3488092160 bytes (3.5 GB) copied, 157.964 s, 22.1 MB/s
I'm not yet sure what the "Bad address" error means, but I suspect it is because dd tried to read beyond the 3.3 GB of memory that I have available.
You can remove the crash.ko module like so when you are finished:
# rmmod crash
Now let's test the newly obtained memory dump to see if it works. I'm going to use the RH Crash Utility with the volatile patch which you can find here:
# ./crash -f /boot/System.map-2.6.27-14-generic /usr/src/linux-source-2.6.27/vmlinux crash.dd --volatile
crash 4.0-8.9
Copyright (C) 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009 Red Hat, Inc.
Copyright (C) 2004, 2005, 2006 IBM Corporation
Copyright (C) 1999-2006 Hewlett-Packard Co
Copyright (C) 2005, 2006 Fujitsu Limited
Copyright (C) 2006, 2007 VA Linux Systems Japan K.K.
Copyright (C) 2005 NEC Corporation
Copyright (C) 1999, 2002, 2007 Silicon Graphics, Inc.
Copyright (C) 1999, 2000, 2001, 2002 Mission Critical Linux, Inc.
This program is free software, covered by the GNU General Public License,
and you are welcome to change it and/or distribute copies of it under
certain conditions. Enter "help copying" to see the conditions.
This program has absolutely no warranty. Enter "help warranty" for details.
GNU gdb 6.1
Copyright 2004 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i686-pc-linux-gnu"...
SYSTEM MAP: /boot/System.map-2.6.27-14-generic
DEBUG KERNEL: /usr/src/linux-source-2.6.27/vmlinux (2.6.27.18)
DUMPFILE: crash.dd
CPUS: 2
DATE: Mon Aug 23 12:31:54 2009
UPTIME: 02:44:55
LOAD AVERAGE: 0.10, 0.17, 0.17
TASKS: 252
NODENAME: --
RELEASE: 2.6.27-14-generic
VERSION: #1 SMP Tue Aug 18 16:25:45 UTC 2009
MACHINE: i686 (1994 Mhz)
MEMORY: 3.2 GB
PID: 0
COMMAND: "swapper"
TASK: c0471340 (1 of 2) [THREAD_INFO: c04aa000]
CPU: 0
STATE: TASK_RUNNING
crash>
So far so good :-)
crash> ps
PID PPID CPU TASK ST %MEM VSZ RSS COMM
0 0 0 c0471340 RU 0.0 0 0 [swapper]
> 0 0 1 f744e480 RU 0.0 0 0 [swapper]
1 0 0 f7448000 IN 0.1 3056 1900 init
2 0 1 f7448c90 IN 0.0 0 0 [kthreadd]
3 2 0 f7449920 IN 0.0 0 0 [migration/0]
4 2 0 f744a5b0 IN 0.0 0 0 [ksoftirqd/0]
5 2 0 f744b240 IN 0.0 0 0 [watchdog/0]
6 2 1 f744bed0 IN 0.0 0 0 [migration/1]
7 2 1 f744cb60 IN 0.0 0 0 [ksoftirqd/1]
8 2 1 f744d7f0 IN 0.0 0 0 [watchdog/1]
9 2 0 f744f110 IN 0.0 0 0 [events/0]
10 2 1 f7460000 IN 0.0 0 0 [events/1]
11 2 0 f7460c90 IN 0.0 0 0 [khelper]
[snip]
crash> foreach files
PID: 0 TASK: c0471340 CPU: 0 COMMAND: "swapper"
ROOT: / CWD: /
No open files
PID: 0 TASK: f744e480 CPU: 1 COMMAND: "swapper"
ROOT: / CWD: /
No open files
PID: 1 TASK: f7448000 CPU: 0 COMMAND: "init"
ROOT: / CWD: /
FD FILE DENTRY INODE TYPE PATH
0 f69c8300 f700c550 f695a3e0 CHR /dev/console
1 f69c8300 f700c550 f695a3e0 CHR /dev/console
2 f69c8300 f700c550 f695a3e0 CHR /dev/console
3 f69c8f00 f720d770 f7243c38 FIFO
4 f69c8780 f720d770 f7243c38 FIFO
5 f69c86c0 f7218990 f7045228 SOCK
6 f69c8b40 f70216e8 f70b6000 DIR inotify
PID: 2 TASK: f7448c90 CPU: 1 COMMAND: "kthreadd"
ROOT: / CWD: /
No open files
PID: 3 TASK: f7449920 CPU: 0 COMMAND: "migration/0"
[snip]
crash> foreach net
foreach: WARNING: net command requires -s or -S option
PID: 0 TASK: c0471340 CPU: 0 COMMAND: "swapper"
No open sockets.
PID: 0 TASK: f744e480 CPU: 1 COMMAND: "swapper"
No open sockets.
PID: 1 TASK: f7448000 CPU: 0 COMMAND: "init"
FD SOCKET SOCK FAMILY:TYPE SOURCE-PORT DESTINATION-PORT
5 f7045200 f6bfe380 UNIX:DGRAM
[snip]
In order to compile the kernel so that you can use the RedHat Crash Utility, you can follow the Ubuntu tutorial. After installing the appropriate packages you may have to run the following command:
sudo apt-get build-dep linux
You should end up with a linux-source*.tar.bz2 file under /usr/src . You should also have at least one folder with the kernel headers for your current kernel. You can extract the .tar.bz2 file as so:
# tar -xjf linux-source*.tar.bz2
Go into the resulting folder and set following flag in the Makefile:
CFLAGS_KERNEL = -g
Copy the .config file from your /usr/src/linux-headers-$(uname -r) folder into the /usr/src/linux-source-$(uname -r) folder.
Now type make. After the kernel is finished compiling, you should end up with a vmlinux file. This is the uncompressed kernel image with the debugging information that you need in order to run the RH crash utility.
For more information on the RH Crash Utility, check out:
Official RH Crash Utility Website
Linux Memory Forensics by A. Walters, M. Cohen and D. Collett.
slides from CEIC
Thursday, August 20, 2009
Briefly: VDP Project
I have volunteered to help with the Volatility Documentation Project (VDP) for Volatility. If you have something you would like to contribute, please feel free to email me at
jamie -{dot}- levy -{at}- gmail -{dot}- com
Contributed documents will appear on the Volatility Google Code website.
We have two new contributions by SAL:
VolReport(win) with an accompaning batch script as well as a manual covering the visual capabilities of Volatility.
Keep them coming :-)
jamie -{dot}- levy -{at}- gmail -{dot}- com
Contributed documents will appear on the Volatility Google Code website.
We have two new contributions by SAL:
VolReport(win) with an accompaning batch script as well as a manual covering the visual capabilities of Volatility.
Keep them coming :-)
Wednesday, August 12, 2009
Installing Volatility Plugins
So you've already installed Volatility using SVN and you want to try out some of the community plugins that people are raving about. Publicly known plugins are listed on the forensics wiki. The wiki contains links to plugins as well as links to blogposts/articles for further information on installation, dependencies and how they work.
Most plugin installation is straightforward where one may simply place the plugin in the memory_plugins directory within the Volatility directory. Some are only slightly more complicated by needing a helper library installed in addition to the plugin itself. Others are even more complicated and require some installation of Python libraries which may or may not need the help of other compiled libraries. Therefore we have three cases for plugin installation (please visit the forensics wiki for more information):
For an example of a simple installation, we will install the volshell plugin. Simply download the volshell.py file and place it into your memory_plugins directory. You can test to make sure that is installed correctly by running Volatility without any arguments and volshell should appear under "Supported Plugin Commands" highlighted below in Figure 1. All other "simple case" plugins should install the same way.

Figure 1: Installation of volshell
The ssdt and threadqueues plugins require that the lists.py library file be placed in the forensics/win32 directory in addition to placing the ssdt.py and threadqueues.py into the memory_plugins folder as before. The driverirp plugin requires the driverscan plugin in order to work. Both of these plugins are placed in the memory_plugins directory.
After placing the files in the appropriate places, check to make sure that the plugins are properly installed by running volatility without any arguments as before and checking under "Supported Plugin Commands" (Figure 1).
For the "most complex cases" other libraries must be installed for the plugin to work properly. First we will look at installing the malfind plugin. First of all, download the malfind.py plugin file and place it in the memory_plugins directory. Now you must install the pydasm and pefile libraries.
In order to install the pydasm library, you will have to do some initial setup including by installing a gcc compiler and make. For this tutorial, we will use MinGW.
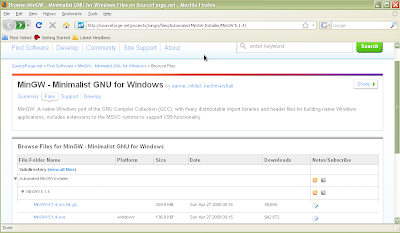
Figure 2: Sourceforge download site for MinGW
Download the windows installer for MinGW from the sourceforge website (Figure 2). Double click to install (Figure 3-9).

Figure 3: Choose "Download and Install"
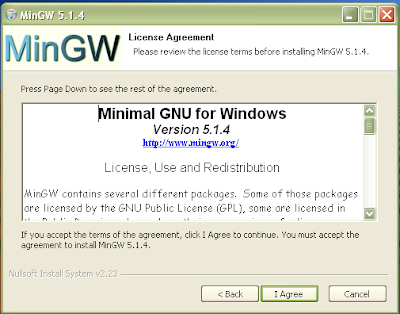
Figure 4: Click "Agree"

Figure 5: Choose "Current"

Figure 6: Choose compilers and MinGW make
You do not necessarily have to install all compilers however, for simplicity, do a full install.
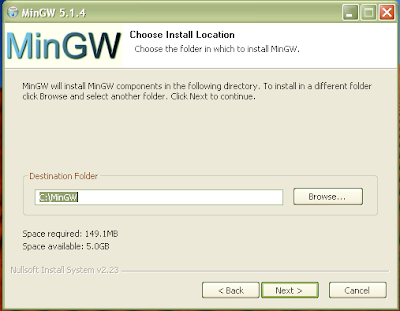
Figure 7: Choose location for installation. The default is fine.
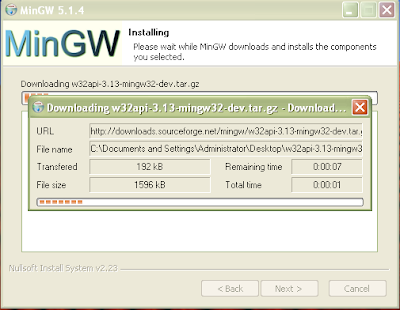
Figure 8: Installing
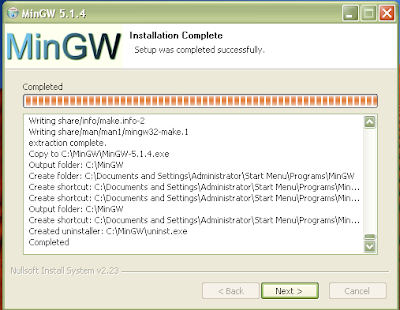
Figure 9: installation complete
Once the installation is complete and you have clicked finish, you will have to make a few adjustments to the installation in order to get things working properly. First of all, we need to have an executable called "make.exe". The make executable for MinGW is appropriately named mingwmake.exe. Simply copy this executable and paste it into the same directory (C:\MinGW\bin) which should result in an identical copy named "Copy of mingwmake.exe". Rename this executable to "make.exe" as shown in Figures 10-11.
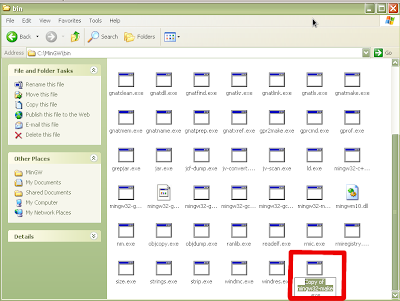
Figure 10: "Copy of mingwmake.exe"
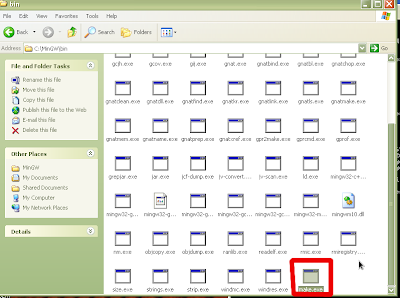
Figure 11: Rename to "make.exe"
Now we have to modify our path to include the executables for MinGW. If you have a regular start menu, click on start and then right click on “My Computer” and choose properties. If you have the classic start menu, just right click on “My Computer” and choose properties. Click on the “Advanced” tab and then click on “Environmental Variables”. Click on the Path system variable towards the bottom of the window and click the “Edit” button. We will append the path of our Python installation to the end of the existing Path variable. Where it says “Variable Value” go to
the end of the line and add the following (if you installed MinGW in a different location, modify appropriately):
;C:\MinGW\bin
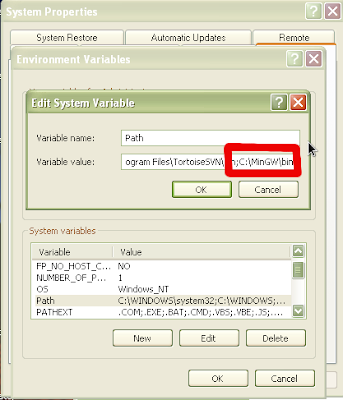
Figure 12: Adding C:\MinGW\bin to the path variable
Now for installing pydasm. Download the source code for libdasm. The easiest way to extract the contents from this tar ball is using 7zip. Once you have 7zip installed, you can associate all zip files by starting the 7zip Filemanager (Start->Programs->7-zip->7-zip File Manager) and clicking on "Tools->Options" and clicking "Select all" in the system tab and "OK" (Figure 13).

Figure 13: Associating zip file types
At this point you are ready to extract the libdasm/pydasm source code. Double click the downloaded pydasm tar ball. You should see the following:

Figure 14: Opening libdasm tar ball with 7-zip
Double click on the libdasm*.tar file inside from within the 7-zip application until you see a folder icon with the name libdasm-1.5 (or other version number):

Figure 15: libdasm folder
Highlight the folder and then click on the extract button and say OK. The folder will extract with all source code inside to the path you choose, or by default the current directory:

Figure 16: Extracting the libdasm source code
Now open a command prompt and change directories until you are in the newly extracted libdasm folder. Type the following commands:
That's it! You've installed pydasm.
Now you are ready to install the pefile library. Grab the zip file or tar ball of the source code and extract is as you did before. Go into that resulting folder and type the following:
Now you've installed pefile. Now you should see the malfind plugin listed under supported plugins for Volatility. All the other plugins that were depend on pefile should work as well if they are installed in the memory_plugins directory.
Installing the volreg plugin requires pycrypto. Simply go the gitweb interface for this project and download the latest git snapshot by clicking on "snapshot". This will download a tar ball file of the source code. Simply extract it as you did before, then open the command prompt and change into that directory. Then type the following:
You've now installed the pycrypto library. Download the volreg tarfile and extract the contents into your Volatility folder by double clicking as before, selecting all three folders and changing the extraction path to your Volatility folder. All files should be placed into the correct location:
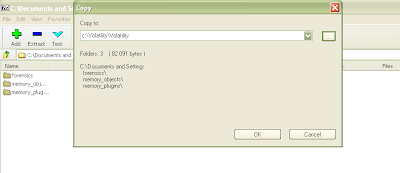
Figure 17: Extraction of volreg into Volatility directory.
Next time we will cover the volrip plugin after I figure out how to get Inline::Python working under windows...
Most plugin installation is straightforward where one may simply place the plugin in the memory_plugins directory within the Volatility directory. Some are only slightly more complicated by needing a helper library installed in addition to the plugin itself. Others are even more complicated and require some installation of Python libraries which may or may not need the help of other compiled libraries. Therefore we have three cases for plugin installation (please visit the forensics wiki for more information):
- Simple Case - only in memory_plugins
- volshell
- IDT
- cryptoscan
- orphan_threads
- keyboardbuffer
- getsids
- moddump
- objtypescan
- symlinkobjscan
- driverscan
- fileobjscan
- pstree
- More Complex Case - also supporting file(s)
- Most Complex Case - installation of supporting libraries
Simple installation of volshell
For an example of a simple installation, we will install the volshell plugin. Simply download the volshell.py file and place it into your memory_plugins directory. You can test to make sure that is installed correctly by running Volatility without any arguments and volshell should appear under "Supported Plugin Commands" highlighted below in Figure 1. All other "simple case" plugins should install the same way.

Figure 1: Installation of volshell
More Complex Cases
The ssdt and threadqueues plugins require that the lists.py library file be placed in the forensics/win32 directory in addition to placing the ssdt.py and threadqueues.py into the memory_plugins folder as before. The driverirp plugin requires the driverscan plugin in order to work. Both of these plugins are placed in the memory_plugins directory.
After placing the files in the appropriate places, check to make sure that the plugins are properly installed by running volatility without any arguments as before and checking under "Supported Plugin Commands" (Figure 1).
Most Complex Cases
For the "most complex cases" other libraries must be installed for the plugin to work properly. First we will look at installing the malfind plugin. First of all, download the malfind.py plugin file and place it in the memory_plugins directory. Now you must install the pydasm and pefile libraries.
In order to install the pydasm library, you will have to do some initial setup including by installing a gcc compiler and make. For this tutorial, we will use MinGW.

Figure 2: Sourceforge download site for MinGW
Download the windows installer for MinGW from the sourceforge website (Figure 2). Double click to install (Figure 3-9).

Figure 3: Choose "Download and Install"

Figure 4: Click "Agree"

Figure 5: Choose "Current"

Figure 6: Choose compilers and MinGW make
You do not necessarily have to install all compilers however, for simplicity, do a full install.

Figure 7: Choose location for installation. The default is fine.

Figure 8: Installing

Figure 9: installation complete
Once the installation is complete and you have clicked finish, you will have to make a few adjustments to the installation in order to get things working properly. First of all, we need to have an executable called "make.exe". The make executable for MinGW is appropriately named mingwmake.exe. Simply copy this executable and paste it into the same directory (C:\MinGW\bin) which should result in an identical copy named "Copy of mingwmake.exe". Rename this executable to "make.exe" as shown in Figures 10-11.

Figure 10: "Copy of mingwmake.exe"

Figure 11: Rename to "make.exe"
Now we have to modify our path to include the executables for MinGW. If you have a regular start menu, click on start and then right click on “My Computer” and choose properties. If you have the classic start menu, just right click on “My Computer” and choose properties. Click on the “Advanced” tab and then click on “Environmental Variables”. Click on the Path system variable towards the bottom of the window and click the “Edit” button. We will append the path of our Python installation to the end of the existing Path variable. Where it says “Variable Value” go to
the end of the line and add the following (if you installed MinGW in a different location, modify appropriately):
;C:\MinGW\bin

Figure 12: Adding C:\MinGW\bin to the path variable
Now for installing pydasm. Download the source code for libdasm. The easiest way to extract the contents from this tar ball is using 7zip. Once you have 7zip installed, you can associate all zip files by starting the 7zip Filemanager (Start->Programs->7-zip->7-zip File Manager) and clicking on "Tools->Options" and clicking "Select all" in the system tab and "OK" (Figure 13).

Figure 13: Associating zip file types
At this point you are ready to extract the libdasm/pydasm source code. Double click the downloaded pydasm tar ball. You should see the following:

Figure 14: Opening libdasm tar ball with 7-zip
Double click on the libdasm*.tar file inside from within the 7-zip application until you see a folder icon with the name libdasm-1.5 (or other version number):

Figure 15: libdasm folder
Highlight the folder and then click on the extract button and say OK. The folder will extract with all source code inside to the path you choose, or by default the current directory:

Figure 16: Extracting the libdasm source code
Now open a command prompt and change directories until you are in the newly extracted libdasm folder. Type the following commands:
make
cd pydasm
python setup.py build -c mingw32
python setup.py install
That's it! You've installed pydasm.
Now you are ready to install the pefile library. Grab the zip file or tar ball of the source code and extract is as you did before. Go into that resulting folder and type the following:
python setup.py build
python setup.py install
Now you've installed pefile. Now you should see the malfind plugin listed under supported plugins for Volatility. All the other plugins that were depend on pefile should work as well if they are installed in the memory_plugins directory.
Installing the volreg plugin requires pycrypto. Simply go the gitweb interface for this project and download the latest git snapshot by clicking on "snapshot". This will download a tar ball file of the source code. Simply extract it as you did before, then open the command prompt and change into that directory. Then type the following:
python setup.py build
python setup.py install
You've now installed the pycrypto library. Download the volreg tarfile and extract the contents into your Volatility folder by double clicking as before, selecting all three folders and changing the extraction path to your Volatility folder. All files should be placed into the correct location:

Figure 17: Extraction of volreg into Volatility directory.
Next time we will cover the volrip plugin after I figure out how to get Inline::Python working under windows...
Monday, August 03, 2009
Volatility SVN
Since the last post on Volatility some of you may be wondering how you may download the newest source of Volatility from the Google SVN repository. Well for Linux it's very easy. After you install subversion using yum or apt-get, you simply follow the instructions on the website:
where [folder name] is replaced by the name of the folder you want to contain the downloaded code.
For Windows users, it's only slightly more complicated. First you must install a subversion client. For this post we will use Tortoise SVN.
Figure 1: Tortoise SVN website
Go to the downloads section and choose the appropriate installer. For this post we are choosing the 32 bit version.
Figure 2: Tortoise SVN website - downloads section
Once you have downloaded the installer, run it. You may see the following security warning, just click Run. All defaults should be fine, so keep clicking next until the installation finishes.
Figure 3 and 4: Running the Tortoise SVN installer
After the installation is complete, you will have to restart your computer. After restart you should see the following menu added when you right click:
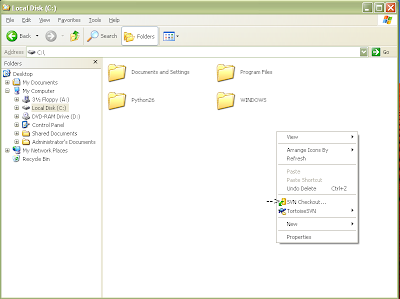
Figure 5: Tortoise SVN right click menu options
Create a folder for the repository (for this run through we will create a folder called Volatility on the root of the drive (C:\). Right click and choose "SVN Checkout" noted in the picture above. After choosing this menu, you should see the following:
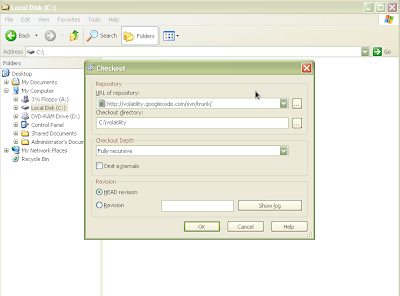
Figure 6: Filling in options to download Volatility
Paste the url of the repository: http://volatility.googlecode.com/svn/trunk/ in the first text box and the location of the newly created folder in the second text box (as shown above). Leave the other options the same as shown above. Press OK. You should see the following as it begins downloading and then finishes:
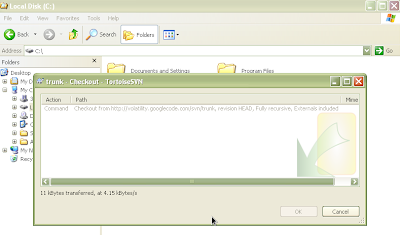
Figure 7 and 8: Downloading Volatility from SVN
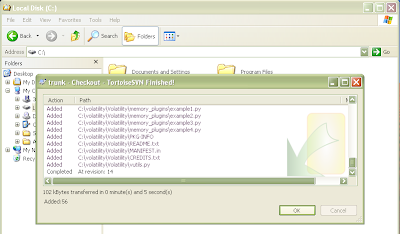
The newly created folder should now contain the SVN repository. This includes another folder named "Volatility" that contains the actual source code. If you go inside the inner Volatility folder you should see the python source code files as shown in Figure 10.
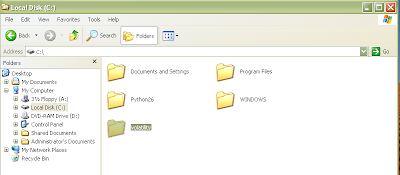
Figure 9 and 10: Newly created folder containing Volatility SVN repository.
To test the newly downloaded code, open a command shell, go inside the Volatility folder (which is inside your newly created folder) and type "python volatility" without the quotes. (This is assuming you have already installed Python, which is covered in the installation manual.) See below:
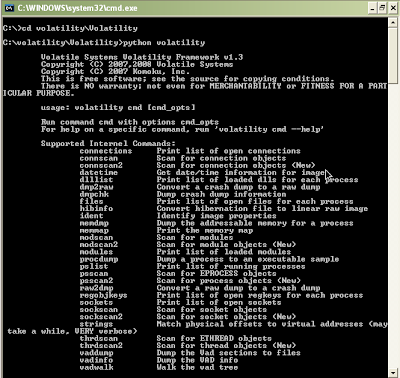
Figure 11: Running Volatility
Now you're set. You have the latest source code for Volatility. Next will be how to install plugins...
$ svn checkout http://volatility.googlecode.com/svn/trunk/ [folder name]where [folder name] is replaced by the name of the folder you want to contain the downloaded code.
For Windows users, it's only slightly more complicated. First you must install a subversion client. For this post we will use Tortoise SVN.

Figure 1: Tortoise SVN website
Go to the downloads section and choose the appropriate installer. For this post we are choosing the 32 bit version.

Figure 2: Tortoise SVN website - downloads section
Once you have downloaded the installer, run it. You may see the following security warning, just click Run. All defaults should be fine, so keep clicking next until the installation finishes.

Figure 3 and 4: Running the Tortoise SVN installer

After the installation is complete, you will have to restart your computer. After restart you should see the following menu added when you right click:

Figure 5: Tortoise SVN right click menu options
Create a folder for the repository (for this run through we will create a folder called Volatility on the root of the drive (C:\). Right click and choose "SVN Checkout" noted in the picture above. After choosing this menu, you should see the following:

Figure 6: Filling in options to download Volatility
Paste the url of the repository: http://volatility.googlecode.com/svn/trunk/ in the first text box and the location of the newly created folder in the second text box (as shown above). Leave the other options the same as shown above. Press OK. You should see the following as it begins downloading and then finishes:

Figure 7 and 8: Downloading Volatility from SVN

The newly created folder should now contain the SVN repository. This includes another folder named "Volatility" that contains the actual source code. If you go inside the inner Volatility folder you should see the python source code files as shown in Figure 10.

Figure 9 and 10: Newly created folder containing Volatility SVN repository.

To test the newly downloaded code, open a command shell, go inside the Volatility folder (which is inside your newly created folder) and type "python volatility" without the quotes. (This is assuming you have already installed Python, which is covered in the installation manual.) See below:

Figure 11: Running Volatility
Now you're set. You have the latest source code for Volatility. Next will be how to install plugins...
Briefly: recordmydesktop
Occasionally I have needed to make screencasts for my students so that they would have something to look at in their own time. There are two tools that make this easy on Linux (both should available in the yum or apt repositories):
Recordmydesktop does as it sounds: it records the desktop. It has options to set the size of the area to record as well as the window you would like to record. I like to choose the window option myself. I also like to record without sound, but you can figure out how to modify the script to remove that option if you so choose.
FFmpeg is a nice tool that allows you to convert, record and stream audio and video. I use it to convert the resulting video from recormydesktop to flv format in order to upload to photobucket or elsewhere.
To make my life easier, I have created the following script that takes in 1-2 arguments. The first argument should be the desired name of the resulting video file. The second argument is an (optional) amount of time to wait before recording. The default wait time is 3 seconds.
When you run the script it waits for you to click on the window that you wish to record by using xwininfo to get the window id number. You will notice that the mouse changes to a + sign as it is waiting for you to click. Once you click the window, it will begin recording that window area after the appropriate wait time has transpired. The video is converted to [chosen filename].flv after you have stopped recording (CTRL+C in terminal from which you started the script).
Feel free to do with as you please. The script can be found below:
Recordmydesktop does as it sounds: it records the desktop. It has options to set the size of the area to record as well as the window you would like to record. I like to choose the window option myself. I also like to record without sound, but you can figure out how to modify the script to remove that option if you so choose.
FFmpeg is a nice tool that allows you to convert, record and stream audio and video. I use it to convert the resulting video from recormydesktop to flv format in order to upload to photobucket or elsewhere.
To make my life easier, I have created the following script that takes in 1-2 arguments. The first argument should be the desired name of the resulting video file. The second argument is an (optional) amount of time to wait before recording. The default wait time is 3 seconds.
When you run the script it waits for you to click on the window that you wish to record by using xwininfo to get the window id number. You will notice that the mouse changes to a + sign as it is waiting for you to click. Once you click the window, it will begin recording that window area after the appropriate wait time has transpired. The video is converted to [chosen filename].flv after you have stopped recording (CTRL+C in terminal from which you started the script).
Feel free to do with as you please. The script can be found below:
#!/bin/bash
#
# Warning: this does not have robust error checking!
bad=67
if [ $# -lt 1 ]
then
echo "Usage: $0 [filename] [[optional time]]"
exit $bad
fi
if [ $# -eq 1 ] #check for arguments
then
time=3 #if one (only filename) exists, sleep for 3 seconds
filename=$1 #set filename
else
time=$2 #else, we'll sleep for $2 seconds
filename=$1 #set filename
fi
recordmydesktop -windowid `xwininfo |grep "Window id:"|sed -e "s/xwininfo\:\ Window id:\ //;s/\ .*//"` -o $filename.ogv -delay $time --no-sound
ffmpeg -i $filename.ogv -b 384000 -s 640x480 -pass 1 -passlogfile log-file $filename.flv
Thursday, July 30, 2009
Cygwin Installation
Note: I am reusing a post from my forensics class at John Jay College. This will be used as a reference for an upcoming post on Volatility module installation. So be patient, there is more to come...
This post goes over an installation of Cygwin which is a Linux-like environment for windows. Since most of you have Windows machines, this will allow you run tools that normally run under Linux/Unix environments.
The setup file is here.
When you download setup, double click it. You should see the following:
Press ``Next'' and choose ``Install from the Internet'' :
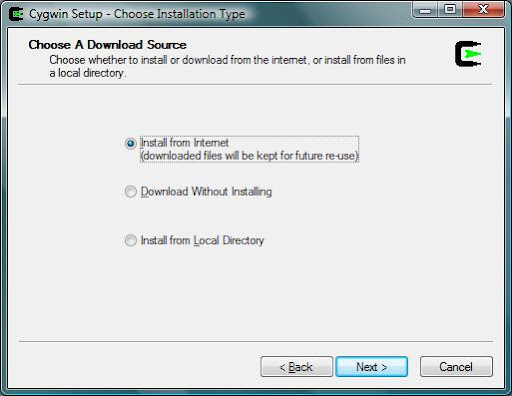
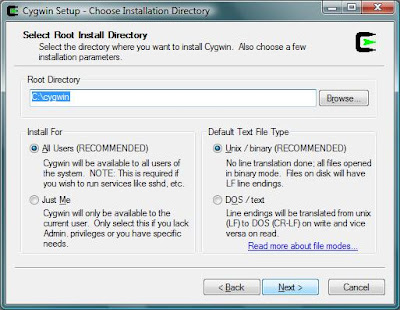
Choose where to install Cygwin (by default it is in C:\Cygwin):
Cygwin will create a directory in which it will store the its files during installation. After installation you can delete the folder. The default location is the desktop:
Select your internet connection. The default is OK:
Select a mirror (mirrorservice.org is good):
Press ``Next'' You should see the following:
Next you will see a list of packages you can download. By default these are organized by category:
If you press the plus signs on the left hand side, it will open up the category and you can select specific packages:
Here is a list of packages you need organized by category:
After you have made your selections, press next for installation to begin. This part is the actual installation, and may take some time. Just let it finish. After it finishes you will be asked if you want to create shortcuts on the desktop. Make sure to click Finish.
Running Cygwin
When you run Cygwin for the first time, it might take a little longer to start up. This is because it is configuring
a few more files for your environment. Then you should get a command line prompt that looks like:
You are now able to work on your programs at home on your windows machines.

This post goes over an installation of Cygwin which is a Linux-like environment for windows. Since most of you have Windows machines, this will allow you run tools that normally run under Linux/Unix environments.
The setup file is here.
When you download setup, double click it. You should see the following:

Press ``Next'' and choose ``Install from the Internet'' :

Choose where to install Cygwin (by default it is in C:\Cygwin):
 |
Cygwin will create a directory in which it will store the its files during installation. After installation you can delete the folder. The default location is the desktop:
 |
Select your internet connection. The default is OK:
 |
Select a mirror (mirrorservice.org is good):
 |
Press ``Next'' You should see the following:

Next you will see a list of packages you can download. By default these are organized by category:
 |
If you press the plus signs on the left hand side, it will open up the category and you can select specific packages:
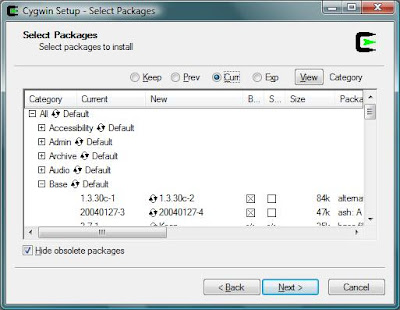 |
Here is a list of packages you need organized by category:
- From the Base category
- Everything
- From the Devel category
- Gcc: C, C++, Fortran compilers
- gcc-mingw: Mingw32 support headers and libraries for GCC
- gcc2: Version X.XX.X [whatever is latest] of C, C++, Fortran compilers
- gdb: The GNU Debugger
- make: The GNU version of the `make' utility
- mingw-runtime: MinGW Runtime
- openssl-devel: The OpenSSL development environment
- From the Editors category
- Nano: A pico clone text editor with extensions [works like pico]
- vim: Vi Improved – enhanced vi editor
- From the Interpreters category
- Perl
- Python
- From the Utils category
- until-linux: Random collection of Linux utilities
- file
- ELFIO
- From the Text category
- less: A file pager program, similar to more(1)
After you have made your selections, press next for installation to begin. This part is the actual installation, and may take some time. Just let it finish. After it finishes you will be asked if you want to create shortcuts on the desktop. Make sure to click Finish.
Running Cygwin
When you run Cygwin for the first time, it might take a little longer to start up. This is because it is configuring
a few more files for your environment. Then you should get a command line prompt that looks like:
You are now able to work on your programs at home on your windows machines.

Wednesday, July 22, 2009
Volatility News
So if you follow me or Moyix on twitter, you will have seen some updates about some cool new plugins by MHL for Volatility. Shouts to MHL for his awesome work!
Other volatility plugins are listed on the Forensics Wiki.
Moyix has also released his slides from his recent talk on combining memory and registry analysis. Awesome stuff!
Volatility was also recently mentioned in Episode 522 of Hak5: Whats in your RAM? along with some other very cool tools like Matthieu Suiche's win32dd
Volatility has been under heavy development lately and has issued a call for bugs. So if you are currently a user and have encountered something odd, please report it so that it may be fixed. You can do so by sending an email to the developer's listserv. In order to get the newest code updates, you can download Volatility from the svn repository simply following the instructions on the site. For installation instructions you can check out the install manual written by yours truly ;-)
Want to learn about memory forensics and the internals of Volatility? Andreas Schuster has posted slides teaching just that!
BTW, Volatile Systems is also currently hiring. So if memory forensics and reverse engineering are within your interests you can apply for a job that includes both!
It's an exciting time and I'm sure there will be much more to come.
Other volatility plugins are listed on the Forensics Wiki.
Moyix has also released his slides from his recent talk on combining memory and registry analysis. Awesome stuff!
Volatility was also recently mentioned in Episode 522 of Hak5: Whats in your RAM? along with some other very cool tools like Matthieu Suiche's win32dd
Volatility has been under heavy development lately and has issued a call for bugs. So if you are currently a user and have encountered something odd, please report it so that it may be fixed. You can do so by sending an email to the developer's listserv. In order to get the newest code updates, you can download Volatility from the svn repository simply following the instructions on the site. For installation instructions you can check out the install manual written by yours truly ;-)
Want to learn about memory forensics and the internals of Volatility? Andreas Schuster has posted slides teaching just that!
BTW, Volatile Systems is also currently hiring. So if memory forensics and reverse engineering are within your interests you can apply for a job that includes both!
It's an exciting time and I'm sure there will be much more to come.
Friday, June 05, 2009
NeFX 2009
Coming to NYC this summer:
NeFX 2009
The First Annual ACM Northeast Digital Forensics Exchange
July 20-21, 2009 @ John Jay College of Criminal Justice/CUNY (NYC)
The ACM Northeast Digital Forensics Exchange (NeFX) is a workshop, sponsored in part by the National Science Foundation, to foster collaboration on digital forensics and information assurance between federal and state law enforcement, academia, and industry. Our goal is to bring together leading practitioners and academics in order to yield partnerships that advance research on digital forensic science through mutual sharing of the problems of practice and research.
This should be interesting. They have some good speakers lined up and some interesting topics for tutorials. Check the website for more details.
NeFX 2009
The First Annual ACM Northeast Digital Forensics Exchange
July 20-21, 2009 @ John Jay College of Criminal Justice/CUNY (NYC)
The ACM Northeast Digital Forensics Exchange (NeFX) is a workshop, sponsored in part by the National Science Foundation, to foster collaboration on digital forensics and information assurance between federal and state law enforcement, academia, and industry. Our goal is to bring together leading practitioners and academics in order to yield partnerships that advance research on digital forensic science through mutual sharing of the problems of practice and research.
This should be interesting. They have some good speakers lined up and some interesting topics for tutorials. Check the website for more details.
Sunday, May 31, 2009
CEIC materials
I would have had this up sooner, but I was out of town last week and the week before was the conference... Anyway, I promised I would post the slides and supporting files for my CEIC classes. I don't have the slides for the foreign language talk, but I didn't promise to give those out ;-)
How to Address ESI Involving Encryption from Disk Level to Individual Files with David Lyman [ppt | pdf]
Spoofing/hacking/memory analysis talk [pdf]
Here is the ARP spoofing perl script we used and some of you requested: [arpspoof.pl]. You must install Nemesis for the script to work, or you can modify it to use another packet crafting program. Also, depending on the distro you might have to modify the path for the arp command (for Fedora it is /sbin/arp). Anyway, you should be able to modify it on your own.
Also, we used Wireshark and Backtrack 4.
For those of you who would like more VM machines to hack into you can go to de-ice.net.
The agenda had changed somewhat for the second talk, since I had taken the class over from someone else at the last second. I would like to thank Prof Bilal Khan for all of his help and his donation of the vulnerable VM :-) Parts of this lab are representative of some of the courses in the Forensic Computing graduate program at John Jay College.
I would also like to thank AAron and Moyix from the Volatility community for their insight as well.
CEIC was a lot of fun, I met a lot of interesting people and had a blast ;-)
How to Address ESI Involving Encryption from Disk Level to Individual Files with David Lyman [ppt | pdf]
Spoofing/hacking/memory analysis talk [pdf]
Here is the ARP spoofing perl script we used and some of you requested: [arpspoof.pl]. You must install Nemesis for the script to work, or you can modify it to use another packet crafting program. Also, depending on the distro you might have to modify the path for the arp command (for Fedora it is /sbin/arp). Anyway, you should be able to modify it on your own.
Also, we used Wireshark and Backtrack 4.
For those of you who would like more VM machines to hack into you can go to de-ice.net.
The agenda had changed somewhat for the second talk, since I had taken the class over from someone else at the last second. I would like to thank Prof Bilal Khan for all of his help and his donation of the vulnerable VM :-) Parts of this lab are representative of some of the courses in the Forensic Computing graduate program at John Jay College.
I would also like to thank AAron and Moyix from the Volatility community for their insight as well.
CEIC was a lot of fun, I met a lot of interesting people and had a blast ;-)
Monday, May 11, 2009
Some Links and Information
Well, it's been a little while since I was last writing on here. Things have been busy, but it will pick up on here soon ;-)
In the mean time, I'll post some interesting things I've come across. I am personally always looking for more information on various computer forensics/security topics. After a recent conversation with some friends of mine from the John Jay College forensics program about how one can keep up with changes in these fields, I thought I might share a few resources that I use. Hopefully some of these links will be interesting to some of you. Instead of focusing on a particular tool, I'm going to focus on the human factor: where do you find people who are interested/experts in these fields? Where can you hear them talk? Where can you interact with them? Where can you get further information about a particular subject?
There are some interesting podcasts out there. Most people already know about them, but what the heck, I'm going to list some anyway in alphabetical order:
SANS' last webcast was a very good overview of what can be accomplished with memory forensics. Also Talk Forensics and PaulDotCom recently had two great podcasts with Harlan Carvey - the man of Windows Forensics. Exotic Liability is a fairly new security podcast that is as extremely interesting and entertaining. The nice thing about most of these podcasts is that you can ask questions in real time by online chat or by calling in to the show.
Well, there are a ton of different forums/listserves for various things. Here is a short list:
There are just too, too many to list. So, I'll tell you what I'll do... I'll give you my (edited) Google Feeds xml file if you are interested in finding more blogs. If you use Google Reader you can just import the file. I've tried to split things up into 3 categories: Forensics, Technical Law and Security. Some things overlap. Don't be offended if you own one of these blogs and aren't "listed correctly." One thing I like about using Google Reader is the ability to search over the blog posts. There are lots of times I remember reading something, but can't quite remember where I found it... this helps.
Twitter
Lots of computer forensics and security professionals can be found on Twitter. I've enjoyed my time on twitter talking with everyone there. Since I'm afraid to leave anyone out, I'll abstain from listing anyone at this point, but most of the people discussed above are on twitter and if you just search for security or forensics you'll end up finding a few more. Also a lot of people who maintain blogs also post links to their twitter profiles. Now of course, there is always the chance that someone could be "disinformational" either on purpose or not (Didier Stevens is not by the way ;-)) but more than likely you will learn a lot from people and will keep up with current events.
LinkedIn
In spite of some of the bad things that have happened on LinkedIn in the past, it is a very helpful tool for networking and gaining information. In addition to establishing contacts with others who are in your field, you can also join groups for your interests. There are several computer forensics and security groups on LinkedIn that are very "happening" as far as member participation. Joining is easy. Some groups may have criteria about who may join, but you can search for groups by subject and decide which ones fit your interests.
Well, that's enough for now... I'm going back to hang out on #volatility on irc.freenode.net ;-)
In the mean time, I'll post some interesting things I've come across. I am personally always looking for more information on various computer forensics/security topics. After a recent conversation with some friends of mine from the John Jay College forensics program about how one can keep up with changes in these fields, I thought I might share a few resources that I use. Hopefully some of these links will be interesting to some of you. Instead of focusing on a particular tool, I'm going to focus on the human factor: where do you find people who are interested/experts in these fields? Where can you hear them talk? Where can you interact with them? Where can you get further information about a particular subject?
Podcasts / Webcasts
There are some interesting podcasts out there. Most people already know about them, but what the heck, I'm going to list some anyway in alphabetical order:
SANS' last webcast was a very good overview of what can be accomplished with memory forensics. Also Talk Forensics and PaulDotCom recently had two great podcasts with Harlan Carvey - the man of Windows Forensics. Exotic Liability is a fairly new security podcast that is as extremely interesting and entertaining. The nice thing about most of these podcasts is that you can ask questions in real time by online chat or by calling in to the show.
Forums / Listserves
Well, there are a ton of different forums/listserves for various things. Here is a short list:
- Listserves
- Linux Forensics Listserv
- Metasploit Listserv
- Volatility Users and Developers Listserves
- Windows Forensics Listserv
Blogs
There are just too, too many to list. So, I'll tell you what I'll do... I'll give you my (edited) Google Feeds xml file if you are interested in finding more blogs. If you use Google Reader you can just import the file. I've tried to split things up into 3 categories: Forensics, Technical Law and Security. Some things overlap. Don't be offended if you own one of these blogs and aren't "listed correctly." One thing I like about using Google Reader is the ability to search over the blog posts. There are lots of times I remember reading something, but can't quite remember where I found it... this helps.
Lots of computer forensics and security professionals can be found on Twitter. I've enjoyed my time on twitter talking with everyone there. Since I'm afraid to leave anyone out, I'll abstain from listing anyone at this point, but most of the people discussed above are on twitter and if you just search for security or forensics you'll end up finding a few more. Also a lot of people who maintain blogs also post links to their twitter profiles. Now of course, there is always the chance that someone could be "disinformational" either on purpose or not (Didier Stevens is not by the way ;-)) but more than likely you will learn a lot from people and will keep up with current events.
In spite of some of the bad things that have happened on LinkedIn in the past, it is a very helpful tool for networking and gaining information. In addition to establishing contacts with others who are in your field, you can also join groups for your interests. There are several computer forensics and security groups on LinkedIn that are very "happening" as far as member participation. Joining is easy. Some groups may have criteria about who may join, but you can search for groups by subject and decide which ones fit your interests.
Well, that's enough for now... I'm going back to hang out on #volatility on irc.freenode.net ;-)
Monday, April 20, 2009
Briefly: CEIC 2009
I will attend and present at the CEIC conference in Orlando, FL. The agenda is available online and it looks like there will be a lot of interesting talks/labs to see and participate in. It should be fun.
Monday, March 30, 2009
Briefly: IWCMC 2009
Jarek, Prof Bilal Khan (BK) and my paper on Permeate was accepted at IWCMC 2009 Computer and Network Security Symposium. The final paper will be available at the Permeate site after some final editing.
Shouts to Jarek and BK!
Shouts to Jarek and BK!
Tuesday, March 10, 2009
Briefly: vol2html update
I have added a very small update to vol2html. Other than fixing some typos and cleaning up the code a little bit, I have added more information about DLL files.
Like the last update you can now see information about what processes have the same dll open.
There will be more... however, I think that it might be better to write a module for Volatility at this time...
Here are vol2html.pl and a new html report.
Let me know if you find any bugs :-)
The venus website is down so if you need to download vol2html you can get it from the new Google code page
Like the last update you can now see information about what processes have the same dll open.
There will be more... however, I think that it might be better to write a module for Volatility at this time...
Here are vol2html.pl and a new html report.
Let me know if you find any bugs :-)
The venus website is down so if you need to download vol2html you can get it from the new Google code page
Thursday, March 05, 2009
PyFlag installation on CentOS 5.2 (updated)
Earlier I wrote about installing Pyflag on Fedora 8. This time, I decided to go for the CentOS install.
First off, this tutorial is not for the faint of heart and as always I take no responsibility if things go wrong on your end.
I got tired of trying to get darcs installed on my CentOS box and instead downloaded the PyFlag tarball. The first thing you will have to do is update Python on your box - I installed 2.6.1 by source.
You must also install all packages mentioned earlier including MySQL for Python and Sleuthkit:
You may have a problem when you install MySQL for Python, however, when it tries to download the setuptools-*.egg file. If you have Python version 2.6 installed you need the following egg file:
setuptools-0.6c9-py2.6.egg.
You can download this into your MySQL-python-1.2.2 directory and change the name to setuptools-0.6c5-py2.6.egg or you can muck around with the ez_setup.py file. However you want to do it.
Now, if you have Python 2.6 installed in addition to your default Python installation, you'll have to copy over some libraries to the new location e.g.
At this point you should be set to begin PyFlag installation.
At that point you are set to run PyFlag. Don't forget to set up MySQL:
You must use quotes around the new-passwd you choose, and don't forget what it is!
Then start PyFlag by typing "pyflag" (without quotes) at the commandline.
By default PyFlag listens on port 8000. So simply open your browser and go to http://127.0.0.1:8000 You can modify settings at this point:
You will then have to initialize the database:
After which you will see a success message:
Now you are ready to start a new case, which you can do under case management.

Give the case a name:
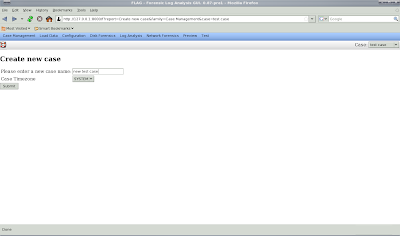
and then you will see confirmation that your case is created:
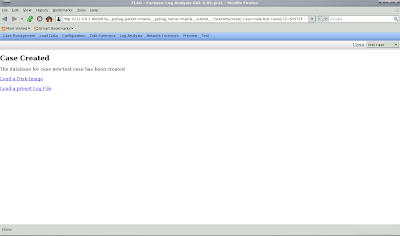
Now you can load your evidence. In this case, I am loading a USB image. Type 0 (zero) for the offset and give your evidence some unique name you'll remember and press submit.
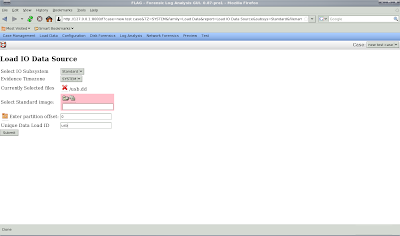
If things work out, you will Sleuthkit will identify the file system type in a mount point (this could be anything, I'm using /usb but it could be D: or whatever):
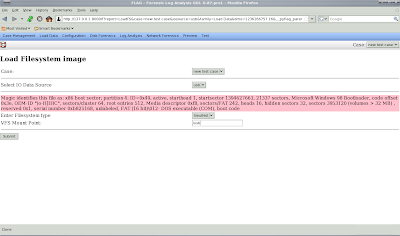
You will then see the uploading dialog.
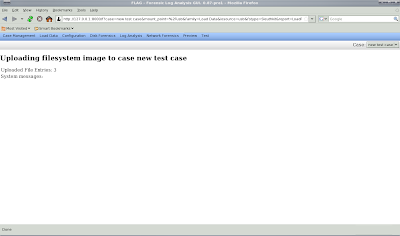
Note: DO NOT BE IMPATIENT! Let it finish uploading. You will notice that it will refresh every now and then as it uploads more from the filesystem. It will then redirect to the analysis screen. You can now browse the filesystem:
First off, this tutorial is not for the faint of heart and as always I take no responsibility if things go wrong on your end.
I got tired of trying to get darcs installed on my CentOS box and instead downloaded the PyFlag tarball. The first thing you will have to do is update Python on your box - I installed 2.6.1 by source.
You must also install all packages mentioned earlier including MySQL for Python and Sleuthkit:
# yum install python-dateutil clamav clamav-server \
mysql mysql-devel mysql-server file-devel python-expect \
zlib zlib-devel openssl python-imaging
You may have a problem when you install MySQL for Python, however, when it tries to download the setuptools-*.egg file. If you have Python version 2.6 installed you need the following egg file:
setuptools-0.6c9-py2.6.egg.
You can download this into your MySQL-python-1.2.2 directory and change the name to setuptools-0.6c5-py2.6.egg or you can muck around with the ez_setup.py file. However you want to do it.
# python2.6 setup.py build
# python2.6 setup.py install
Now, if you have Python 2.6 installed in addition to your default Python installation, you'll have to copy over some libraries to the new location e.g.
# cp -R /usr/lib/python2.4/site-packages/pexpect.py* \
/usr/local/lib/python2.6/site-packages/
# cp -R /usr/lib/python2.4/site-packages/PIL \
/usr/local/lib/python2.6/site-packages/
# cp -R /usr/lib/python2.4/site-packages/python-dateutil \
/usr/local/lib/python2.6/site-packages/
# cp /usr/lib/python2.4/pyexpect.py* \
/usr/local/lib/python2.6/
At this point you should be set to begin PyFlag installation.
# ./configure
# make install
At that point you are set to run PyFlag. Don't forget to set up MySQL:
# /sbin/chkconfig mysqld on
# /sbin/service mysqld start
# mysqladmin -u root password 'new-passwd'
You must use quotes around the new-passwd you choose, and don't forget what it is!
Then start PyFlag by typing "pyflag" (without quotes) at the commandline.
By default PyFlag listens on port 8000. So simply open your browser and go to http://127.0.0.1:8000 You can modify settings at this point:

You will then have to initialize the database:

After which you will see a success message:

Now you are ready to start a new case, which you can do under case management.

Give the case a name:

and then you will see confirmation that your case is created:

Now you can load your evidence. In this case, I am loading a USB image. Type 0 (zero) for the offset and give your evidence some unique name you'll remember and press submit.

If things work out, you will Sleuthkit will identify the file system type in a mount point (this could be anything, I'm using /usb but it could be D: or whatever):

You will then see the uploading dialog.

Note: DO NOT BE IMPATIENT! Let it finish uploading. You will notice that it will refresh every now and then as it uploads more from the filesystem. It will then redirect to the analysis screen. You can now browse the filesystem:

Wednesday, February 25, 2009
Briefly: IDA Pro on CentOS 5.2
This is almost a non-post, but who knows, it might be useful to someone... So today I while installing Ida Pro on CentOS, I hit a small snafu. Everything went well for key extraction: here's a nice tutorial for that. However after I retrieved the key, I placed it according to the README file in the $HOME/.idapro directory.
However, when running it I was faced with the following problem:
I noticed that my library was incompatible since it was libstdc++.so.6. Luckily, there are ``compat'' packages that contain these older libraries. You can install them with yum:
At this point, IDA Pro starts up nicely:


However, when running it I was faced with the following problem:
$ ./idal
./idal: error while loading shared libraries: libstdc++.so.5: cannot open shared object file: No such file or directory
I noticed that my library was incompatible since it was libstdc++.so.6. Luckily, there are ``compat'' packages that contain these older libraries. You can install them with yum:
# yum install -y compat-libstdc++-33.i386
At this point, IDA Pro starts up nicely:



Subscribe to:
Comments (Atom)